Short name: DMN+
Score: 4
Problem addressed / Motivation
- The dynamic memory network (DMN), obtained high accuracy on a variety of language tasks. However, it was not shown whether the architecture achieves strong results for question answering when supporting facts are not marked during training or whether it could be applied to other modalities such as images.
Idea / Observation / Contribution
- We propose a new input module which uses a two level encoder with a sentence reader and input fusion layer to allow for information flow between sentences.
- For the memory, we propose a modification to gated recurrent units (GRU)
- We show that the changes in the memory module that improved textual question answering also improve visual question answering.
Formulation / Solver / Implementation
- Input Module
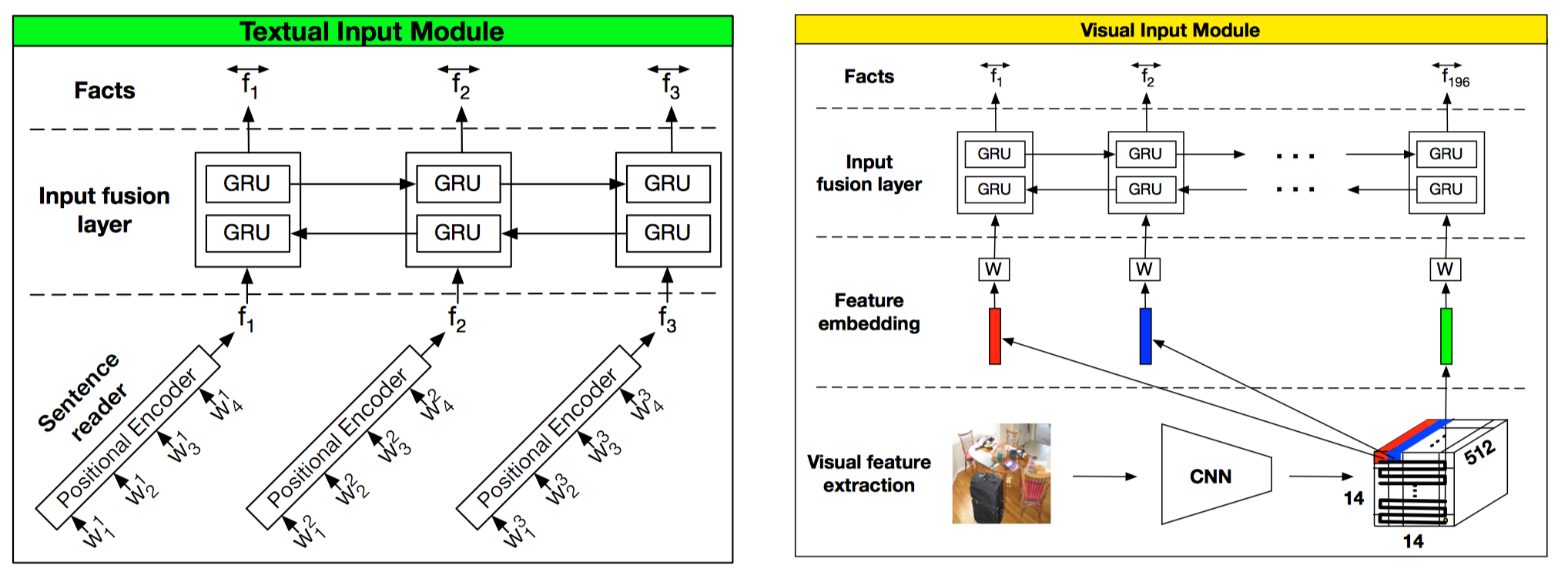
There are the text input module and image input module.- Text Input Module
- positional endoder M is the length of sentence and $l_j$ is a vector with structure
- Input fusion layer(bi-directional GRU)
- Input Module for VQA
- Utilize VGG19 Model for extract image features
- We first rescale the input image to 448 × 448 and take the output from the last pooling layer which has dimensionality d = 512 × 14 × 14. The pooling layer divides the image into a grid of 14 × 14, resulting in 196 local regional vectors of d = 512.
- Text Input Module
- The Episodic Memory Module
- First, calculate the attention gate $g_t^i$
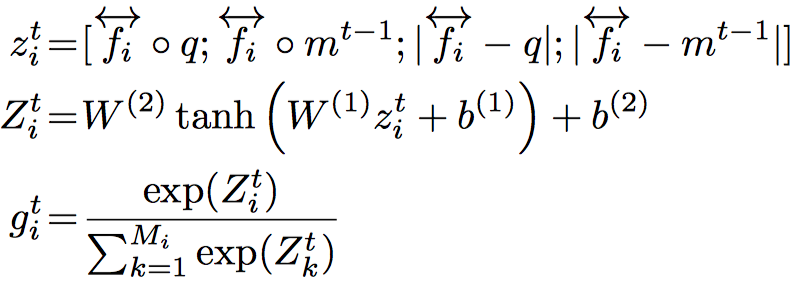
- Then there are two attention methods
- Soft attention
Just calculate the weighted sum. However the main disadvantage to soft attention is that the summation process loses both positional and ordering information. - Attention based GRU
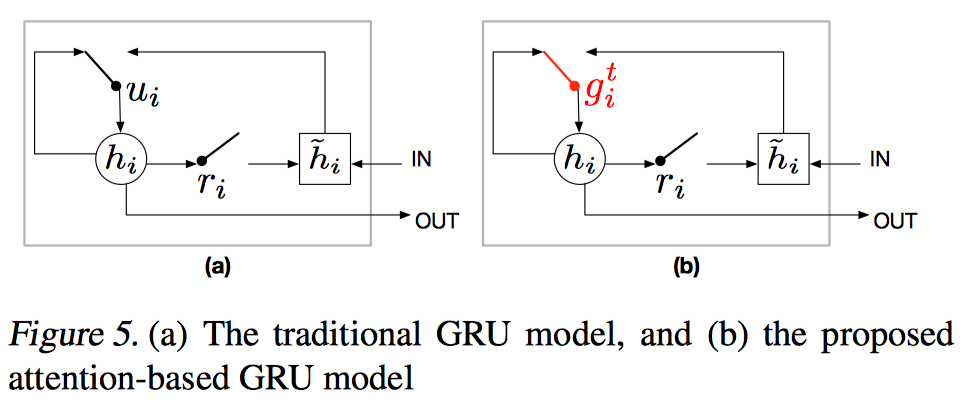 To produce the contextual vector $c^t$ used for updating the episodic memory state $m^t$ , we use the final hidden state of the attention based GRU.
To produce the contextual vector $c^t$ used for updating the episodic memory state $m^t$ , we use the final hidden state of the attention based GRU.
- Soft attention
- Episode Memory Updates
- First, calculate the attention gate $g_t^i$
Useful info / tips
- $m^0 = q$
Evaluation
Dataset
- bAbI-10k
- DAQUAR-ALL visual dataset
- The Visual Question Answering (VQA) dataset
Metrics
- Adam Optimizer
- Xavier Initializer for word embedding in Text QA
- Random uniform initializer for weights in VQA
Results
- Outperforms baseline and other state-of-the-art methods across all question domains (All) in both test-dev and test-std, and especially for Other questions, achieves a wide margin compared to the other architectures, which is likely as the small image patches allow for finely detailed reasoning over the image.
- The Number questions may be not solvable for both the SAN and DMN architectures, potentially as counting objects is not a simple task when an object crosses image patch boundaries.
Resource
Project page
There is a web app for DMN+.
Source code
There is the tensorflow implementation of DMN+.
Dataset
Other paper reading notes
not yet completed