Notes for “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”
Type
Reading comprehension
Size
650K training examples for the Web search results, each containing a single (combined) evidence document, and 78K examples for the Wikipedia reading comprehension domain, containing on average 1.8 evidence documents per example.
Resouces
http://nlp.cs.washington.edu/triviaqa/
Source
Evidence
Our evidence documents are automatically gathered from either Wikipedia or more general Web search results.
Finally, to support learning from distant supervision, we further filtered the evidence documents to exclude those missing the correct answer string and formed evidence document sets as
Question-answer pairs
First we gathered question-answer pairs from 14 trivia and quiz-league websites. We removed questions with less than four tokens, since these were generally either too simple or too vague.
Answer Form
92.85% of the answers are titles in Wikipedia, 5 4.17% are numerical expressions (e.g., 9 kilometres) while the rest are open ended noun and verb phrases.
Question Form
The average question length is 14 tokens indicating that many questions are highly compositional.
Reasoning used to answer TriviaQA questions: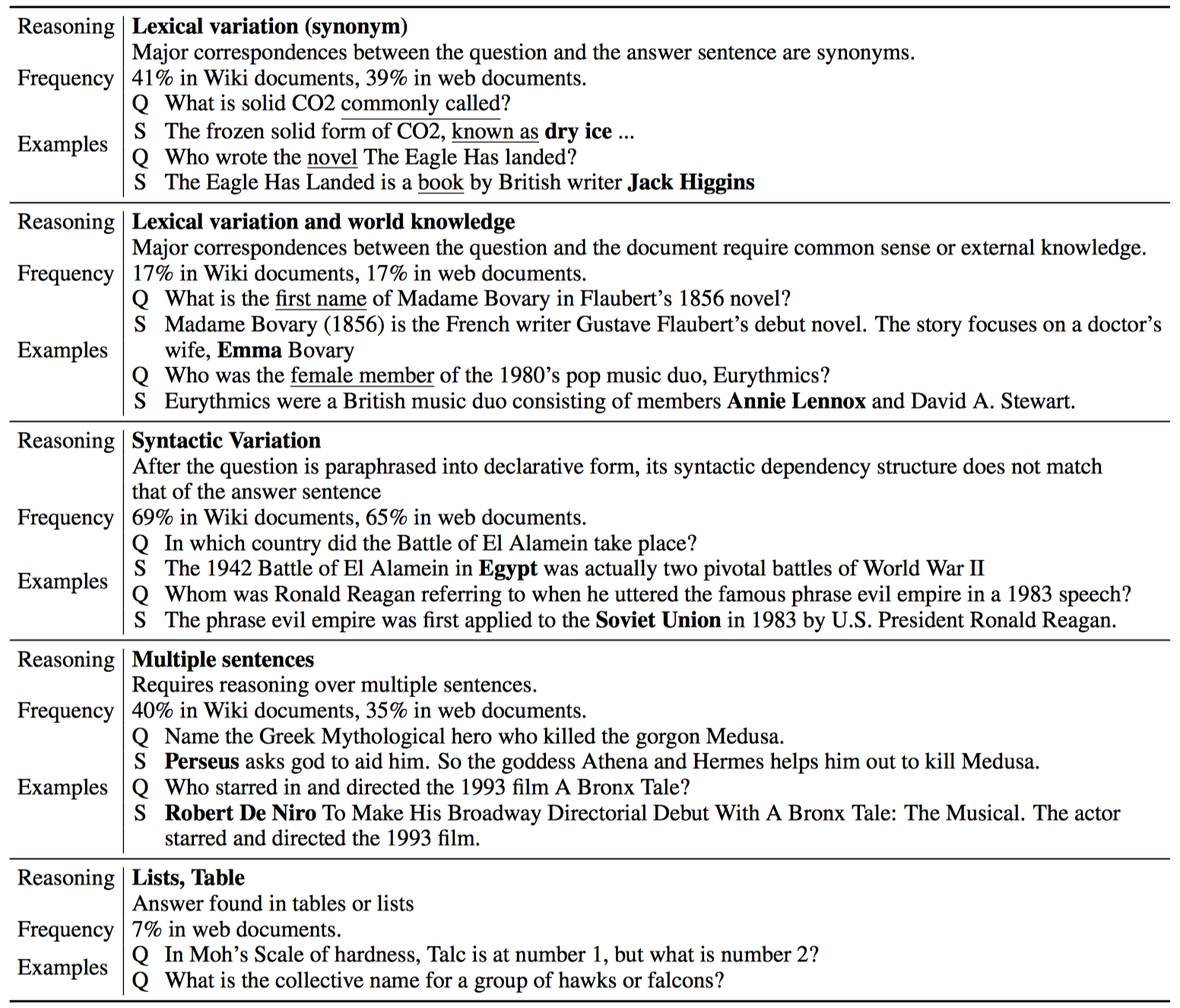
Related
Compared to SQuAD, over three times as many questions in TriviaQA require reasoning over multiple sentences. Moreover, 17% of the examples required some form of world knowledge. Question-evidence pairs in TriviaQA display more lexical and syntactic variance than SQuAD. This supports our earlier assertion that decoupling question generation from evidence collection results in a more challenging problem.
Baseline Methods
We used a random entity baseline and a simple classifier inspired from previous work (Wang et al., 2015; Chen et al., 2016), and compare these to BiDAF (Seo et al., 2017), one of the best performing models for the SQuAD dataset.
Results
For both Wikipedia and web documents, BiDAF (40%) outperforms the classifier (23%). The oracle score is the upper bound on the exact match accuracy. 9 All models lag significantly behind the human baseline of 79.7% on the Wikipedia domain, and 75.4% on the web domain.
Metrics
We use the same evaluation metrics as SQuAD exact match (EM) and F1 over words in the answer(s).
Shortcomings
Because we gather evidence using an automated process, the documents are not guaranteed to contain all facts needed to answer the question.